眼瞼結膜画像からヘモグロビン値を正確に推定するのに重要な要素は不明
東京大学医学部附属病院は7月19日、スマートフォンで撮影した眼瞼結膜写真からヘモグロビン値を予測する機械学習・深層学習モデルを構築したと発表した。この研究は、同大大学院医学系研究科小児医学講座の加登翔太氏(医学博士課程)、加藤元博教授、エルピクセル株式会社の茶木慧太氏、髙木優介氏、河合宏紀氏らの研究グループによるもの。研究成果は、「British Journal of Haematology」に掲載されている。
画像はリリースより
(詳細は▼関連リンクからご確認ください)
貧血の診断には、血液検査によりヘモグロビン値の低下を確認する必要があるが、眼瞼結膜の赤みの程度を見ることで、貧血の有無を推測する身体診察法も以前より用いられてきた。しかし、眼瞼結膜の赤みからは、貧血がありそうかどうかをおおまかにしか判断できず、ヘモグロビン値がどのくらいかを正確に推定することはできないばかりか、その精度も高くないという課題があった。これまでも複数の先行研究で、機械学習を用いて眼瞼結膜の写真からヘモグロビン値を推定するモデルが開発されてきたが、機械学習の中でも深層学習を用いた研究はほとんどなかった。深層学習アルゴリズムはブラックボックスで、ヘモグロビン値の推定においてどのような要素が重要であるかは明らかになっていなかった。
入院・通院患者の画像から眼瞼結膜領域のみを自動抽出するアルゴリズム構築
研究グループは、まず、東京大学医学部附属病院の小児科に通院中あるいは入院中の150人の患者について、スマートフォンで撮影した眼瞼結膜写真と、同じ日に診療検査として行った血液検査の結果(ヘモグロビン値)を得た。次に、このうちの90人の眼瞼結膜写真を用いて、撮影した写真から眼瞼結膜領域のみを自動的に抽出するアルゴリズムを構築した。ここでは深層学習によるセグメンテーションモデルに上述の写真を学習させることで、高精度に眼瞼結膜の領域を抽出できた。
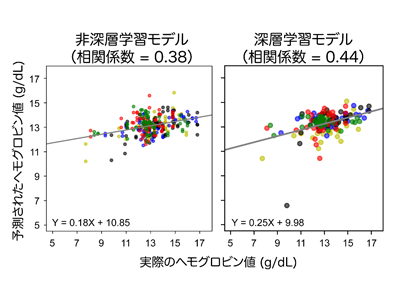
非深層および深層学習モデルでヘモグロビン値を予測、深層学習のほうが高精度
続いて、このセグメンテーションモデルを用い、150人全員の症例について眼瞼結膜の領域を抽出し、血液検査で測定したヘモグロビン値と合わせて機械学習モデルに学習させた。ここでは機械学習モデルとして非深層学習モデルと深層学習モデルを使用した。非深層学習モデルでは、眼瞼結膜領域からさらに色の情報を抽出し、ヘモグロビン値を予測した。深層学習モデルでは、抽出した眼瞼結膜領域をそのまま使用してヘモグロビン値を予測した。その結果、非深層学習モデルよりも深層学習モデルの方が精度よくヘモグロビン値を予測できた。
画像解析には、眼瞼結膜の下半分の領域が重要
最後に、深層学習モデルを用いたヘモグロビン値の予測において、眼瞼結膜領域のどの部分が特に重要なのかを調べるためにGrad-CAMを用いた可視化を行った。Grad-CAMは、勾配加重クラス活性化マッピング(gradient-weighted class activation mapping)の略で、深層学習を用いた画像解析モデルにおいて、画像のどの部分が重要であるかを解析・可視化する手法である。
この結果、貧血の実測値と予測値が近い症例では眼瞼結膜の下半分が特に注目されていたことがわかった。一方、実測値と予測値の乖離が大きい症例では眼瞼結膜の下半分以外に注目してしまっていることがわかった。
病院に行かずに貧血の有無を推定できるスマホアプリの開発に応用できる可能性
研究結果から、深層学習モデルにおいて特に眼瞼結膜の下半分の領域に注目することが重要であることが世界で初めて明らかになったため、さらに精度のよい深層学習モデルを構築することにより、将来的には臨床実装に向けた技術の発展につながることが期待される。「スマートフォンで撮影した眼瞼結膜写真をもとにAIモデルを開発したことから、誰でも、どこでも、病院に行くことなく貧血の有無を推定できるスマートフォンのアプリケーションの開発に応用できる可能性がある。具体的には医療アクセスの乏しい中・低所得国や、鉄欠乏性貧血をきたしやすい小児・妊婦などでの簡便な貧血スクリーニングへ応用できると考えられる」と、研究グループは述べている。
▼関連リンク
・東京大学医学部附属病院 プレスリリース


