米USMLEで合格点に迫る性能を示したChatGPT、日本では?
金沢大学は3月18日、ChatGPTに日本の医師国家試験を解かせるために最適化されたプロンプトを開発し、このプロンプトとGPT-4を用いることで、最低合格得点率を上回ることに成功したと発表した。この研究は、同大融合研究域融合科学系の野村章洋准教授と株式会社MICINの共同研究グループによるもの。研究成果は「PLOS Digital Health」にオンライン掲載されている。
画像はリリースより
(詳細は▼関連リンクからご確認ください)
GPT(Generative Pretrained Transformer)に代表される大規模言語モデル(LLM)の登場により、臨床現場や医学研究の支援ツールとしての応用が期待されている。2023年初頭に、ChatGPTが米国の医師国家試験(USMLE)で合格点に迫る性能を示し話題となったが、英語以外の言語圏での医師国家試験における性能は、これまで十分に評価されていなかった。
プロンプト最適化・GPT-4搭載のChatGPT、2023年2月実施の日本の試験に挑む
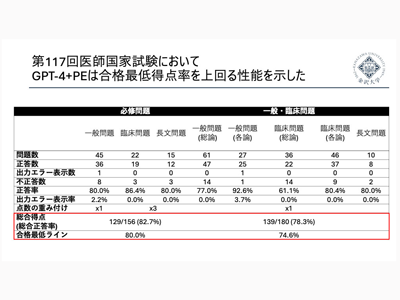
今回の研究では、GPT-3.5ならびにGPT-4モデルが搭載されたChatGPTを用いて、ChatGPTへの指示(プロンプト)を最適化した上で、日本の医師国家試験を解答させた際の正答率を検討した。まず、2022年2月に実施された第116回医師国家試験を用いて、問題内に画像データを有さない290問を、プロンプト最適化用データセットとして使用した。そして正答率が最も高くなるようなプロンプトを決定した。その最適化されたプロンプトを用いて、GPT-4モデルが搭載されたChatGPTに入力し、2023年2月に行われた第117回医師国家試験から問題内に画像データを有さない262問を用いてその正答率を評価した。
必修問題82.7%、一般問題77.2%の正答率
その結果、必修問題で82.7%、一般問題で77.2%の正答率を達成した。これは、同回試験における受験生の最低合格得点率をいずれも上回っていた。さらに、ChatGPTが誤答を出力した原因を分析したところ、医学知識の不足、日本特有の医療制度に関する情報不足、そして計算問題での誤りの3点が主な要因だったことがわかった。
課題は残るものの、医療用AIの基盤モデルの一つとなることが期待される
GPT-4と最適化されたプロンプトを共に用いることで、ChatGPTは日本の医師国家試験で最低合格得点を超える可能性があることが示された。このような LLM は、人間の受験者を対象とした問題に解答するという次元を超えて、医療・ヘルスケア分野のアンメット・メディカルニーズを満たす最良の「相棒」となる可能性を秘めていると考えられる。一方、現時点では、専門的な医学知識をどのように継続的に学習をさせ、さらに最新かつ正確な出力を担保するかなどの課題が残っている。「このような LLM は近い将来、臨床的有効性と安全性が科学的に示され、医療用AIの基盤モデルの一つとなることが期待される」と、研究グループは述べている。
▼関連リンク
・金沢大学 プレスリリース

