医学分野におけるChatGPTの性能や注意点を科学的に検証
横浜市立大学は11月15日、OpenAI社のChatGPTに医学に関する質問をする際の注意点を科学的に検証したと発表した。この研究は、同大医学部循環器・腎臓・高血圧内科学の土師達也助教(次世代臨床研究センター(Y-NEXT)兼任)、平和伸仁准教授、田村功一主任教授らの研究グループによるもの。研究成果は、「International Journal of Medical Informatics」にオンライン掲載されている。
画像はリリースより
(詳細は▼関連リンクからご確認ください)
ChatGPTを含む自然言語処理を可能とする生成系人工知能は、そのユーザビリティの高さから世界規模で急速に利用が拡大している。利用者は会話をするようにChatGPTにあらゆる事項について質問をし、回答を得ることができる。ChatGPTはインターネット上に存在する膨大なありとあらゆるテキストデータを学習して構築されており、医学に関する質問に対して正しい答えを導出するように設計されたわけではない。したがって、ChatGPTが医学に関する質問に対して正しい答えを導き出せるのか、どのような場合に誤答をする可能性があるのかについては、科学的な検証がなされていない。
一方で、すでに世界中にユーザーが拡大しており、身の回りの医学・保健に関する質問をChatGPTに尋ねる事例も増えていると考えられる。ChatGPTの回答内容は必ずしも常に正しいとは限らないが、自然な文章内容であることから、利用者は一見してその回答内容の正誤について判断ができないケースも多くある。今後、ChatGPTを含む人工知能を正しく利用していくにあたって、その性能と注意点を科学的に検証し、明らかにしていく必要に迫られている。
日本の医師国家試験3年分を出題、最新モデルGPT-4で正答率向上
研究グループは、日本の医師国家試験3年分をChatGPTに出題し、その正答率と回答の一貫性を集計した。この研究にはChatGPTの旧モデルであるGPT-3.5と、最新モデルであるGPT-4の両方が使用された。その結果、GPT-4はGPT-3.5に比較して著しい正答率の向上を認めた(56.4%から81.0%へ)。回答の一貫性に関しても、大幅に向上していることがわかった(56.5%から88.8%へ)。
各分野の正答率、総文献数と有意に関連
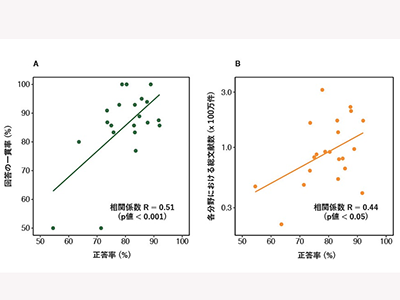
次に、試験問題について、その出題形式(単肢選択問題/多肢選択問題/計算問題)や出題内容(循環器学・小児科学など分野ごと)に応じて分類し、正答率に関連する因子について検証を進めた。ChatGPTは、インターネット上の膨大なテキストデータを学習して構築されている。その情報量には分野ごとに偏りがある可能性があり、それはChatGPTの性能にも影響を与えた可能性がある。そこで、インターネット上の情報量の1つの指標として、その分野においてそれまでに出版され、世界的な学術文献・引用情報データベースであるWeb of Science Core Collection(Clarivate社)に収蔵された全ての文献数を集計した。このデータベースには世界中で刊行された主要な学術雑誌(約2万1,000誌)の文献が収録されている。
その結果、各分野における正答率は、その分野における総文献数と有意に関連することが多変量解析を含む科学的解析によって明らかになった。この他、出題形式や回答の一貫性(同一問題を連続して出題した際の回答内容の一致率)が正答率に関連することがわかった。
新薬・新興感染症など、相対的に情報量が乏しい分野に注意
これまで、医学に関する質問に対するChatGPTの性能や注意点について、科学的に検証を行った研究は乏しかった。そのため、同研究は先駆的な位置付けとなる。一方で、同研究はその規模や手法に限定的な点があるため、今後、さらなる検証が必要と考えられる。同研究結果は、ChatGPTの性能がその分野における情報量の格差の影響を受けている可能性を示している。例えば、新薬や新興感染症などの相対的に情報量が乏しい分野に関して質問をする際には、回答が正しいかどうか注意が必要であることを示唆している。また、ChatGPTの回答内容は必ずしも常に正しいとは限らないが、自然な文章内容であることから、利用者は一見してその回答内容の正誤について判断ができないケースが多くあるとしている。
今回の研究結果は、利用者がChatGPTの回答内容の正誤を判断する上での一助となることが期待される。医学に関する質問に対するChatGPTの性能と注意点の理解は、医学分野での実際の運用に加え、一般市民が日常の医学・保健衛生上の問題解決や知識獲得・教育を促進していく上でも非常に有用と考えられる、と研究グループは述べている。
▼関連リンク
・横浜市立大学 プレスリリース


