手術を伴う皮質脳波信号を使用しても、聞き取りやすい音声の合成は困難だった
東京工業大学は1月20日、頭皮で記録された脳波信号(EEG)から音声を直接再構築するために有望な手法を開発したと発表した。この研究は、同大科学技術創成研究院の吉村奈津江准教授(科学技術振興機構さきがけ研究員兼務)、明石航大学院生(研究当時)、神原裕行助教、緒方洋輔特任助教(研究当時)、小池康晴教授、ルドビコ・ミナチ特定准教授らの研究グループによるもの。研究成果は、ドイツ科学技術誌「Advanced Intelligent Systems」に掲載されている。
画像はリリースより
コンピュータ処理技術の飛躍的な革新に伴い、脳活動信号から脳内の情報を読み出すブレイン・コンピュータ・インタフェースに関する研究が近年、盛んに進められている。この技術を用いて、脳内の情報処理過程を知るために何十年にもわたって注目してきた課題が次第に明らかになってきた。
音声情報の読み出しに関しては、電極を頭蓋骨下の脳皮質表面に埋め込む手術を伴う皮質脳波信号(ECoG)を使用して聴覚処理に関連する脳領域から直接信号を取得し、それによって音声合成が試みられている。しかし深層学習など、機械学習の最近の進歩にもかかわらず、ECoGを使用しても、聞き取りやすい音声の合成は依然として困難な状況である。
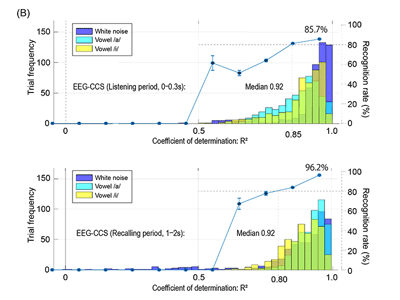
吉村准教授らは、EEGから脳内の神経活動を機械学習により推定し、筋活動、指の動きなど、これまでEEGからでは困難だと考えられてきた情報を抽出することに成功している。そこで今回、音声認識や音声合成に用いられているメルケプストラムという音声情報を表現しているパラメータをCNNモデルで推定し、物理的に提示または想起された母音をEEGから合成することを目的に研究を行った。
CNNを用いて推定し復元した音源、約8割の高い精度で判別可能
研究では、32か所のEEG電極から、母音の「ア」「イ」および白色雑音を聞いている時と、その後、聞いた音声を想起している時のEEGを記録し、聞かせた音源のパラメータ信号をEEGから畳み込みニューラルネットワーク(CNN)を用いて推定して、音源を復元。復元された音声が耳で聞き分けられるかどうか聞き取り判別試験を行ったところ、全ての参加者の脳波データにおいて、おおよそ8割程度の判別が可能だった。
このような高い精度でCNNが音声情報を抽出できたことから、CNNが音源推定に利用した脳の領域と信号の時間的なタイミングが、脳内の音声処理過程を間接的に反映していると推察。その領域を調べた結果、脳内の聴覚処理において、何の音かを検知するための信号が処理される「Whatストリーム」と呼ばれる脳領域群が主に使われていることが判明した。
脳内の聴覚・音声・言語処理の理解に貢献、聴覚検査の客観的な手法として使用できる可能性
これは、コンピュータが抽出した脳内の特徴が脳科学的にも妥当であったことを示唆している。さらに、音を聞いている時と音を思い出した時ではCNNが抽出した脳領域に違いがあり、個人ごとの脳領域の違いもみられた。今回は、2種類の母音の違いだけを調べたが、この技術をさらに進歩させることで、個人の脳内の聴覚・音声・言語処理のさらなる理解に貢献できるものと期待される。
今回の研究成果により、耳で聞き分けられる聴取性能の高い音声がEEGから再構成された。これにより、本人がどのように聞こえているかを第三者に伝えることができると考えられ、聴覚検査の客観的な手法として使える可能性がある。「脳のどの領域が聴覚・音声・言語処理に関係しているのかについての理解を深め、ブレイン・コンピュータ・インターフェイスなどのさまざまな将来のアプリケーションへの道を開く可能性がある」と、研究グループは述べている。
▼関連リンク
・東京工業大学 ニュース


