DNA多型の効果サイズは小さく、予測モデル作成が困難
東北大学は8月12日、複数の数理モデルを比較し、「過学習」を抑えるような機械学習手法を用いた手法が、うつ病症状をはじめとする精神疾患のリスク予測に有用なことが明らかになったと発表した。これは、同大東北メディカル・メガバンク機構の高橋雄太医員、植木優夫助教(現・長崎大学教授)、田宮元教授、富田博秋教授らの研究グループによるもの。研究成果は、「Translational Psychiatry」に掲載されている。
画像はリリースより
うつ病などの精神疾患の発症は、多数のDNA多型が関係すると想定されている。一方、精神疾患の発症をDNA多型情報から予測モデルを用いてリスク予測する研究には大きな課題があった。それは多くの精神疾患の発症には多数のDNA多型が関係しているにもかかわらず、DNA多型の効果サイズが小さいため、真に疾患との関連を示すDNA多型を検出することが難しいことが挙げられる。結果的に予測モデルの過学習が生じ、予測精度の向上は限られてしまう。
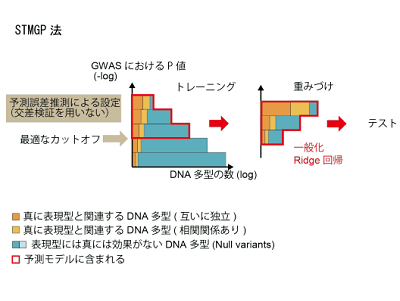
STMGP法は、DNA多型の選択をして、さらにGWASの統計量に基づいてDNA多型に重みづけを行うことで予測モデルの過学習(学習の段階では性能が良いかのように高い予測精度を示すが、実際のテストの段階では予測精度が低くなること)を抑え、高精度な予測ができるように開発された機械学習手法。研究グループは今回、このSTMGP法が実際に精神疾患発症のリスク予測をするのに有効であるかについて検討した。
STMGP法が最も高い予測精度示す、精神疾患のDNA多型情報からのリスク予測に有用な可能性
研究では、東北メディカル・メガバンク計画によって収集された宮城県在住の3,685人分のDNA多型情報を用いて予測モデルの機械学習を行い、岩手県在住の3,048人のデータを用いて予測モデルの精度を評価した。初めに、うつ病に関する症状のデータと、さまざまなシミュレーション解析により作成されたデータを用いて予測精度の検討をした。次に、STMGP法と、現時点で頻用されている最先端の予測モデル(Polygenic Risk Score法、genomic best linear unbiased prediction、summary-data-based best linear unbiased prediction、Bayes R法、Ridge回帰法)について、それぞれの予測精度と過学習の程度を比較した。
その結果、うつ病に関する症状のリスク予測においては、他モデルの予測精度と比較して有意差はないものの、STMGP法は最も高い予測精度を示した。また、シミュレーション解析の検討において、STMGP法は複雑な遺伝素因をもつ精神疾患のDNA多型情報からのリスク予測に有用である可能性を示した。
「今後研究が進み、STMGP法といった過学習を抑えた機械学習の手法を用いることで精密なうつ病のリスク予測が可能となれば、うつ病やその他の精神疾患への罹患しやすさ、しづらさに関わる病態の一部を、DNA多型に基づいて説明でき、より個々人に適した予防法や医療の提供が期待される」と、研究グループは述べている。
▼関連リンク
・東北大学 プレスリリース

