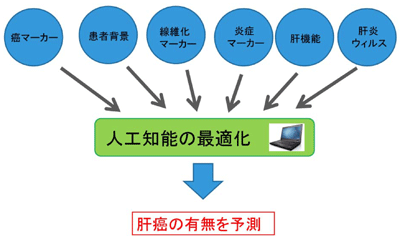
学習アルゴリズムと学習パラメーターを自動抽出
東京大学医学部附属病院は5月30日、ディープラーニングを含むさまざまな手法から、収集された患者データから得られる予測能を最大化する学習アルゴリズムと学習パラメーターを自動抽出するフレームワークを作成し、患者データを用いた肝がんの有無の予測精度を検討したと発表した。この研究は、同院検査部の佐藤雅哉助教、矢冨裕教授、同院消化器内科の建石良介特任講師、小池和彦教授らと、島津製作所基盤技術研究所AIソリューションユニットの梶原茂樹主幹研究員らの研究グループによるもの。研究成果は「Scientific Reports」に掲載されている。
画像はリリースより
多要因が組み合わさり発症するさまざまながんに対し、単一腫瘍マーカーでの存在予測には限界がある。従来がんの有無の予測に使用される腫瘍マーカーは有効な手段だが、日常の診療においては腫瘍マーカー以外にもたくさんの情報が収集されるため、なるべく多くの情報を統合して診断を行うことが望ましいと考えられている。
正診率87.3%、AUROC値0.940と高精度
研究グループは、線形回帰モデル、ニューラルネットワーク、決定木、サポートベクターマシン、ディープラーニングなど、さまざまな手法から収集された患者データから得られる予測能を最大化する学習アルゴリズムと学習パラメーターを自動抽出するフレームワークを作成し、日常の診療で得られる患者データを用いて、どの程度正確に肝がんの有無が予測できるかを検討した。なお、同フレームワークは目的とする予測対象(研究では肝がんの有無)と日常診療で得られる患者データセットを入力すると、フレームワーク内で最も予測精度の高い学習アルゴリズムと学習パラメーターが抽出され、最適な学習モデルが自動的に作られる仕組みになっている。
まず、1997年1月〜2015年5月までに東京大学医学部附属病院を受診した肝疾患患者の中から、肝がんの予測モデルに入力する年齢、性別、身長、体重、HBs抗原とHCV抗体、アルブミン、ビリルビン、AST、ALT、ALP、γGTP、血小板値、AFP、AFP-L3分画、PIVKA-IIの16項目と肝がんの有無の情報が収集可能であった1,582人(肝がん患者539人、非肝癌患者1,043人)を用いて、肝がんの予測モデルの作成と精度の評価を行った。対象患者1,582人を、各アルゴリズムの訓練を行うための訓練データ(1,266人)、最適な学習パラメーターを抽出するための検証データ(158人)、作成された学習モデルの精度を検証するための評価データ(158人)の3つにわけて検討を行った。
機械学習のフレームワークにより抽出された最適アルゴリズムは勾配ブースティング決定木で、eta=0.08、gamma=0.02、max depth=1、minimal_child_weight=1.5、nround=300、subsample=0.5、colsample_bytree=0.9が最適パラメーター値として抽出された。同アルゴリズムと最適パラメーターを用いた評価データにおける肝がんの正診率、AUROC値は、それぞれ87.3%、0.940と高い精度を示した。
同学習モデルは、患者年齢や腫瘍マーカー、アルブミン値などといった因子に注目し、肝がんの有無の判定を行っていた。また、ディープラーニングは同データに対する最適なアルゴリズムではなく、正診率とAUROC値は83.5%と0.884だった。腫瘍マーカーを単独で用いた際の正診率とAUROC値はそれぞれAFPで70.7%と0.766、AFP-L3分画で74.9%と0.644、PIVKA-Ⅱで71.1%と0.683だった。
肝がんに留まらず、他分野への応用にも期待
現在、電子カルテのクラウド化などの試みも進んでおり、将来的にプラットフォームのクラウド化などにより症例集積が加速すれば、同システムのさらなる精度の向上が期待できる。
研究グループは、「患者を対象とする医学研究においては、同意取得の必要性や倫理的な側面への配慮から、数万人の患者サンプルを収集することは現実的に困難だ。このような状況の中で、現存するデータに対して予測能を最大化するアルゴリズムを抽出するというアプローチはとても重要と考えられる。本フレームワークは肝がんに限らず、さまざまなデータに適用が可能であり他分野への応用も期待される」と、述べている。
▼関連リンク
・東大病院 プレスリリース

