眼底検査装置からのマルチモダリティ画像情報を用いて構築
理化学研究所(理研)は3月28日、眼底検査装置からのマルチモダリティ画像情報を用いて、緑内障を自動診断できる機械学習モデルを構築したと発表した。この研究は、同光量子工学研究センター眼疾患クラウド診断融合連携研究チームの秋葉正博チームリーダー、横田秀夫副チームリーダー(同センター画像情報処理研究チームリーダー)、安光州客員研究員、東北大学大学院医学系研究科眼科学教室の中澤徹教授らの共同研究グループによるもの。研究成果は「Journal of Healthcare Engineering」に掲載されている。
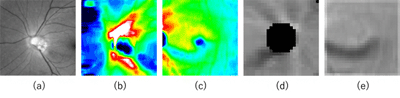
画像はリリースより
緑内障は、高眼圧、網膜への血流量低下など、さまざまな危険因子により視神経が損傷を受け、やがて失明に至る疾患で、日本では中途失明原因の第1位となっている。自覚性がなく、一度失った視野や視力を治療によって取り戻すことができないため、眼科検診により早期発見し、その進行を止める早期治療を行うことが求められている。
従来の緑内障の診断では、カラー眼底画像や眼底の2次元断面を測定する光干渉断層計(OCT)画像で、視神経乳頭と黄斑の形状に対する読影を行うことにより主観的に判断することから、客観性がないとされていた。
一方、機械学習による眼科疾患検出においては、大量の眼底写真から糖尿病網膜症の自動診断システムがアメリカ食品医薬局(FDA)で認可されるなど、世界的に大きな進展がある。しかし、緑内障を対象とするマルチモダリティ画像情報を大量に収集することは難しく、緑内障の詳しい診断は不可能だった。
AUC=0.963を示す高い診断精度
研究グループは今回、眼底検査装置で視神経乳頭と黄斑を撮影したデータから抽出したマルチモダリティ画像情報に対して、緑内障の自動診断を行う機械学習モデルの構築を試みた。緑内障208眼(MD値:-3.90±3.80dB)と健常149眼(MD値:-0.21±1.15dB)について、眼底検査装置を用いて撮影された視神経乳頭と黄斑のデータ(カラー眼底画像1種とOCT画像4種)から、それぞれマルチモダリティ画像情報を抽出。そしてこれらの情報に対して、転移学習とランダムフォレストを組み合わせることにより、少数の情報から緑内障の自動診断を行う機械学習モデルを構築し、非常に高い診断精度(AUC=0.963)を得ることに成功した。
研究グループは「本成果は、各症例に対して提案した機械学習モデルにより、緑内障の確信度を提示することで、緑内障の早期発見につながると期待できる」と、述べている。
▼関連リンク
・理化学研究所 プレスリリース

