2型糖尿病の分類、臨床現場で活用しにくいという課題があった
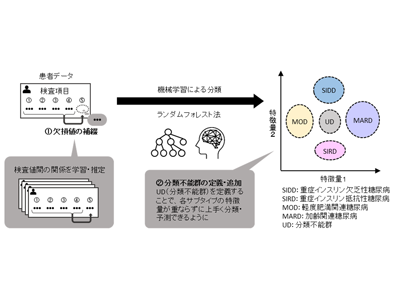
千葉大学は10月17日、ランダムフォレストと呼ばれる機械学習の手法に欠損データの補綴と、予測確率の低い分類カテゴリー(分類不能群)の定義・追加を組み合わせることにより、日常的に得られる臨床データのみを用いて、2型糖尿病のサブタイプを高精度に予測できる機械学習モデルを開発したと発表した。この研究は、同大大学院医学研究院の川上英良教授、福島県立医科大学糖尿病内分泌代謝内科学講座の田辺隼人助教、島袋充生教授らの研究グループによるもの。研究成果は、「Diabetologia」に掲載されている。
画像はリリースより
(詳細は▼関連リンクからご確認ください)
糖尿病は、インスリンが十分に働かないために、血液中のブドウ糖の量が多い状態が続く病気である。日本における糖尿病の大半を占めるのが2型糖尿病で、その患者数は予備軍を含めると1000万人を超えると推定されている。膵臓から分泌されるインスリンによって、血糖値は一定の範囲にコントロールされるが、2型糖尿病ではインスリン分泌の減少や、インスリンへの反応の低下により、血糖値が高くなる。血糖値が高い状態が長期間続くと、血管がダメージを受け、失明、神経障害、脳卒中、心筋梗塞、腎不全などの重篤な合併症のリスクにさらされる。
先行研究では、2型糖尿病は重症インスリン欠乏性糖尿病、重症インスリン抵抗性糖尿病、軽度肥満関連糖尿病、加齢関連糖尿病の4種類のサブタイプに分類されるが、病気の状態や原因、合併症の有無・種類、治療反応が個人で異なるため、患者の糖尿病のサブタイプを知った上で、それに合わせた治療を進めることが重要である。2型糖尿病の分類には個々の患者のインスリンの分泌・感受性に関連するデータが必要であるが、日常臨床データには含まれない項目のため、臨床現場で活用しにくいという課題があった。また理論上は糖尿病のサブタイプは長期にわたって安定的と考えられているが、従来法での分類では経時的なサブタイプの変化がしばしば生じ、サブタイプ分類は長期的な治療計画には使いにくいと考えられてきた。そこで今回の研究では、日常臨床データだけで2型糖尿病のサブタイプを高精度かつ一貫性をもって予測できるモデルの開発を試みた。
臨床データから糖尿病サブタイプを予測する機械学習モデル開発
研究グループはランダムフォレストと呼ばれる教師あり機械学習の手法を用いた予測モデルを開発した。その際、検査値間の関係を学習することで、日常臨床データの値からインスリンに関するデータの値を推定可能にした。また先行研究では4つだった2型糖尿病のカテゴリーに、分類予測確率の低いカテゴリー(分類不能群:UD)を定義・追加することで、各サブタイプの特徴量の分布が重ならずに上手く分類・予測できるようになった。
従来法での分類結果に対し高い精度示す、SIDDは100%・MARDは97.9%
得られたモデルによるサブタイプ予測は、教師データである従来法での分類結果に対し、82.9〜94.0%という高い精度を示した。またサブタイプ分類の一貫性の検討のため、観察期間前後のサブタイプ予測の結果を比較したところ、前後でサブタイプが一致していた割合は重症インスリン欠乏性糖尿病(SIDD):100%、重症インスリン抵抗性糖尿病(SIRD):68.6%、軽度肥満関連糖尿病(MOD):94.4%、加齢関連糖尿病(MARD):97.9%となり、従来法よりも高い一貫性を示した。
日常診療データからのサブタイプ予測、糖尿病の個別化医療実現への寄与が期待
今回得られた予測モデルによって、従来必須であった項目が欠損していても日常臨床データを用いたサブタイプ分類が可能となり、患者一人ひとりの合併症リスク(失明、神経障害、脳卒中、心筋梗塞、腎不全など)や治療反応性を、手持ちのデータから高精度に予測できるようになった。本成果により、日常診療データからの糖尿病のサブタイプ予測が可能となり、臨床現場におけるサブタイプ分類、糖尿病の個別化医療実現への大きな寄与が期待される。「一貫性の高いサブタイプ分類が可能となったことで、個々の患者の合併症リスクや治療反応性に基づいた長期的な治療計画や予後の推定にも本モデルが貢献できると考えられる」と、研究グループは述べている
▼関連リンク
・千葉大学 プレスリリース

